Why Serverless Backends Break Databases
Fri Jan 16 2026
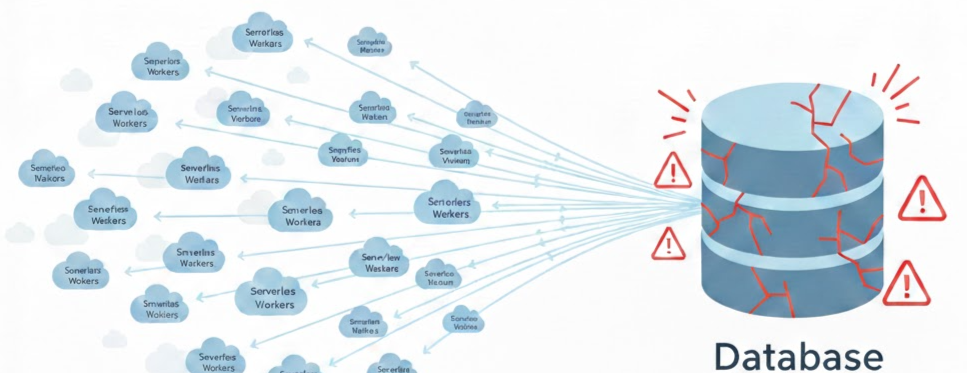
How connection pools quietly save your application from costly outages
Serverless scales automatically!
Absolutely.
"Databases don't."
…and that's exactly where production sys tems break.
If you've deployed backends on Cloudflare Workers, AWS Lambda, or Vercel, you've likely encountered this warning:
Never connect directly to your database from serverless functions.
Initially, this seems overly cautious. After all, shouldn't your backend communicate with its own database?
Let's explore why this guidance exists, what actually fails in production, and how connection pools serve as the essential mediators that keep your systems running smoothly.
The Hidden Cost of "Infinite Scale"
Serverless platforms scale by doing something deceptively simple:
They spin up more instances of your code whenever traffic increases.
That means:
- 1 user → 1 worker
- 100 users → 100 workers
- 10,000 users → 10,000 workers
Each of those workers is:
- Stateless
- Short-lived
- Potentially running in different regions
Now here's the dangerous assumption:
Each worker can just open a database connection.
That assumption breaks reality.
Databases Are Not Serverless
Most traditional databases — PostgreSQL, MySQL, MariaDB — were never designed for this pattern.
They have hard connection limits.
| Database | Typical Max Connections |
|---|---|
| PostgreSQL | ~100–500 |
| MySQL | ~150–300 |
| Managed DBs | Often lower |
Now compare that with serverless scaling.
If 500 Lambda instances all open their own DB connection at the same time:
Your database collapses.
Not because queries are slow
but because connections themselves are expensive.
Why Database Connections Are Expensive
Opening a database connection is not just "opening a socket".
It involves:
- TCP handshake
- Authentication
- TLS negotiation
- Memory allocation on the DB server
- Backend process or thread assignment
Now imagine doing that:
- On every request
- From ephemeral workers
- That appear and disappear constantly
That's not scaling, that's thrashing.
Visualizing the Problem
Worker 1 ───▶ DB
Worker 2 ───▶ DB
Worker 3 ───▶ DB
...
Worker 500 ─▶ DB (catches fire)
Each worker thinks it's being reasonable. The database disagrees.
Enter the Connection Pool (The Middleman)
A connection pool is not magic.
It's discipline.
Instead of letting every worker open a connection:
You allow only a small, fixed number of database connections — and reuse them.
The pool sits between your app and the database.
How a Connection Pool Actually Works
- The pool opens a limited number of DB connections (e.g. 10 or 20 total)
- Workers request a connection from the pool
- If one is free → they get it
- If not → they wait
- When finished → the connection is returned
No explosions. No connection storms. No database panic.
Bad Pattern: Direct DB Connection from Serverless
import { Client } from "pg";
export async function handler() {
const client = new Client({
host: process.env.DB_HOST,
user: process.env.DB_USER,
password: process.env.DB_PASSWORD,
database: process.env.DB_NAME,
});
// New connection per invocation
await client.connect();
const result = await client.query("SELECT * FROM users LIMIT 10");
await client.end();
return {
statusCode: 200,
body: JSON.stringify(result.rows),
};
}
Why this fails:
- Each invocation opens a new TCP + TLS connection
- Hundreds of instances do this simultaneously
- Connection limits are hit before CPU or memory
- Latency spikes before failures appear
Reusing a global client does not fix horizontal scaling.
Correct Pattern: Connection Pool / Database Proxy
import { Pool } from "pg";
const pool = new Pool({
connectionString: process.env.DATABASE_PROXY_URL,
max: 10,
idleTimeoutMillis: 30_000,
connectionTimeoutMillis: 2_000,
});
export async function handler() {
const client = await pool.connect();
try {
const result = await client.query(
"SELECT * FROM users LIMIT 10"
);
return {
statusCode: 200,
body: JSON.stringify(result.rows),
};
} finally {
// returned to pool, not closed
client.release();
}
}
What changed:
- The database never sees more than 10 connections
- Connections are reused
- Load increases → waiting increases, not failures
That's controlled degradation instead of chaos.
Cloudflare Workers–Friendly Pattern (HTTP-Based Proxy)
Cloudflare Workers can't maintain raw TCP connections.
import { PrismaClient } from "@prisma/client";
const prisma = new PrismaClient({
datasources: {
db: {
url: process.env.DATABASE_PROXY_URL,
},
},
});
export default {
async fetch() {
const users = await prisma.user.findMany({ take: 10 });
return new Response(JSON.stringify(users), {
headers: { "Content-Type": "application/json" },
});
},
};
Why this works:
- No raw DB sockets from workers
- Proxy manages pooled connections
- Workers stay stateless
- Database stays sane
The Mental Model That Actually Helps
Think of it like a restaurant:
- Workers = customers
- Database = kitchen
- Connection pool = waiters
You don't let 500 customers walk into the kitchen.
You let a few trained waiters handle the traffic.
Final Takeaway
- Serverless scales horizontally
- Databases scale vertically
- Direct connections ignore that mismatch
Connection pools translate between those worlds.